X
May 20, 2026
The AI wave is driving massive changes in how organizations deliver and secure software. 93% of enterprises now ship AI-generated code to production.1 Simultaneously, every application security vendor in the market is racing to attach the word "AI" to their scanner. The pitch writes itself: point the robot at your repository, wait an hour, get a security report. No agents to install. No instrumentation overhead. No six-figure contract or analyst salary. AI will find the vulnerabilities, write the fixes and let you get on to more pressing matters in your day.
Seasoned cybersecurity professionals know it’s best to approach unbelievable claims with healthy skepticism and to seek the data behind the promises. We found that AI security scanners can quickly become costly sources of noise and chaos for organizations that deploy them, but they show promise when used thoughtfully.
What we found will change how you think about the AI scanning pitch:
The full numbers, the false positives, and what to do instead are below.
Contrast Labs put the theory to the test to help separate truth from hyperbole. As part of our project, we ran three approaches:
We tested each of these approaches against two distinct mid-sized codebases. The first codebase was 1.8 million lines of code, and the second was 50,000, both with a heavy concentration of Java, the kind of applications that power an actual enterprise product. The target codebases were well-established, having undergone years of SAST, DAST, IAST, RASP, bug bounty programs and annual pentests. This ensures that we’ve weeded out the easy findings, and that we’re giving the models a real workout.
To begin, we started with the most basic test: a Simple Mode scan run to full coverage on our 1.8-million-line enterprise application. Here are the results:
That $315 number might feel like a win until you consider that scanning weekly means you’re on the hook for $16,000 annually for this single application alone. That said, the costs of actually managing the risk are much higher because they require us to triage, understand, and fix the code's flaws.
Before we get to the labor math, it is worth being precise about the kinds of errors a scanner produces, because the costs differ. A false positive (Type I error) is a finding that flags safe code as vulnerable. The cost is wasted triage time. A false negative (Type II error) is a real vulnerability that the scanner misses. The cost is the undetected risk that remains in production. Both matter. AI scanning in our testing generated substantial Type I error rates, which drive the triage labor cost as outlined below. Type II error rates are harder to measure, but the fact that only 5% of findings were flagged by all three tools suggests the Type II problem is also significant. A finding that only one scanner catches is either a genuine insight or noise. Without triage, you cannot tell which.
AI scanning doesn’t change the most fundamental challenge in AppSec: the costs of prioritizing and remediating findings far outstrip the costs of finding them.
Let’s examine triage costs for a moment: A security engineer costs around $150,000 per year, fully loaded, or about $72 per hour. Conservative triage time per finding is 30 minutes. This is the time it takes to read the finding, open the source code file, trace the code, and make a judgment call. Running the math on 3,560 findings:
Total triage labor: $72/hr x ½ hr/finding x 3,560 findings
Total triage labor: ~$128,000.
We spent $315 to compile a list of findings that would cost us $128,000 just to triage, before we even begin fixing anything. Put another way, this is nearly a full year of work for our security engineer to understand the risks in this single application. Of course, this math assumes every finding is worth triaging; many are not.
Next, we wanted to understand the quality of the findings. While some AI models can infer a great deal about application execution from the code itself, our Simple Mode scan was not up to the challenge and we found that the vast majority of the findings were simply noise. As examples, we looked into a pair of findings, both CRITICAL SQL injections. We were initially excited to have found hidden risks, but that excitement was soon replaced by disappointment.
A quick investigation revealed that the first finding was a query built with correct parameterized PreparedStatement binds, and did not represent an actual exploitable vulnerability: a classic false positive.
The code associated with the second finding is below, with the “vulnerable” code highlighted:
private static final String GET_KEY =
"select name, value from my_tb where name = '%s'";
private static final String MASTER_KEY_NAME = "MASTER_KEY";
String retrieveKey(final Connection connection) throws SQLException {
String key = "";
try (PreparedStatement totalEntries =
connection.prepareStatement(String.format(GET_KEY, MASTER_KEY_NAME))) {
try (ResultSet rs = totalEntries.executeQuery()) {
while (rs.next()) {
final String name = rs.getString(1);
final String value = rs.getString(2);
if (MASTER_KEY_NAME.equals(name)) {
key = value;
}
}
}
}
return key;
}
Using String.format to create a command that will be passed into a SQL string is code behavior worth noting; it’s a common vector for attacker-supplied inputs to reach a SQL database in a classic SQL injection attack. Also, it’s noteworthy that there’s no evident code here that validates, normalizes, or sanitizes the function inputs, so you might see where this finding came from. But this is not a CRITICAL vulnerability. In this code, MASTER_KEY_NAME is a hardcoded constant. There is no user input anywhere near this query, and zero risk in this bit of code.
These behaviors recurred throughout our Simple Mode scan. While the model made a reasonable assumption on where a vulnerability might lie, it was wrong because it lacked the full context of the running application. Getting to the point of understanding this required human time and expertise, something the AI was supposed to be reducing, not exacerbating.
The obvious response is to see if we can generate cleaner findings by using a smarter AI. In our next test, we used specialized sub-agents, one per vulnerability class, which were capable of deeper analysis with full data flow tracing. The findings it produced were genuinely better. Our Multi-agent Mode scan uncovered a mass-assignment issue in a password-change flow that allowed privilege escalation. It traced and verified the underlying data flow, confirmed the source and sink and provided a true finding worth having.
Smarter AI did not solve our problem; however, it simply shifted costs around. During our testing, we chose not to burn the necessary tokens to complete the Multi-agent Mode scan against the full 1.8M-line codebase, but our partial results showed that the API cost for that level of quality across the full repository would be between $43,000 to $107,000. That’s an astronomical amount for a single scan against a single application repository. And while triage costs are drastically lower under this model, they’re not gone. We estimated that the all-in cost for a quality agent’s scan of a 1.8M-line application ranges from $65,000 to $150,000, which isn’t significantly different from the cost of our Simple Mode scan.
.png?width=650&height=366&name=Social%20LinkedIn%20Newsletter%20-%20Cost%20of%20Pure%20AI%20Scanning%20(1).png)
To see whether these patterns held across a different scale and a commercial scanner, we ran a second experiment on a 50,000-line Java application using three scanners simultaneously. Simple Mode and the Multi-agent Mode ran on Sonnet 4.6, the same model as the first experiment. The third was Claude Security, Anthropic's dedicated application security scanner built on Claude Opus 4.7. The commercial scanner was supposed to give a cleaner answer. Instead, it exposed the same problem from another angle.
Tracking the API costs associated with running our 3 different models against our 50k-line codebase results in the following outcomes:
Scaling these results linearly to a 2-million-line application, and you get $120, $2,000, and $9,440, respectively. This is a very optimistic view of how these models scale, however. Linear extrapolation assumes that cost grows proportionally to code volume, but context windows do not behave that way at scale. As file sizes grow and more code gets loaded per analysis pass, prompt overhead compounds. Larger files mean more tokens per call and higher costs per finding.
Codebase composition matters here, too. Repetitive codebases full of generated DAOs, framework boilerplate and test scaffolding compress more efficiently than tightly engineered code where every line carries weight. A tightly-crafted, dense codebase will cost more to analyze per line than a monolith padded with CRUD endpoints. Both of those factors push real costs above what linear projections suggest. Based on how these models actually behave on large codebases, a Claude Security run on a 2 million-line enterprise application is likely to cost $40,000 to $50,000 in compute costs, possibly higher depending on code density.
There is a time element associated with AI assessment to consider as well. Claude Security took 45 minutes to analyze the 50,000-line codebase. Scaling that linearly to a 2-million-line enterprise application and you are looking at roughly 30 hours per scan. That said, again, real-world large applications won’t scale in this neat and tidy manner, however. The same compounding dynamics that inflate the API costs at scale also inflate scan times. Larger context windows per pass, more passes required per file and greater coordination overhead across the full repository all increase the time required for AI application scanning. A 30-hour theoretical floor is wildly optimistic.
We triaged every high- and critical-severity finding from this second experiment. The results were not encouraging. A meaningful portion was outright false positives. Others were coding patterns that look concerning in isolation but function correctly and without risk in context. Several of the highest-rated findings pointed to code with no reachable execution path from any user-controlled input, dead code and unused functions, flagged as critically important anyway. The severity ratings themselves were inconsistent, particularly from the Simple Mode scan, which applied wildly different risk scores to functionally identical patterns across the same codebase. There was no coherent logic driving the numbers.
To make matters worse, the different models gave wildly different opinions of where the risks were in our application. Fifty-nine unique findings surfaced in total. Forty-two of these findings were flagged by a single model, but not corroborated by either of the other two. Three scanners. Same codebase. Only three of them, five percent, were flagged by all three.
Sadly, unanimous agreement wasn’t the cleanest signal of a good finding. The two cleanest confirmed true positives in the entire dataset were an authorization bypass vulnerability and an Insecure Direct Object Reference (IDOR) flaw. Both were caught by the Multi-agent Mode scanner and Claude Security. Neither appeared in our Simple Mode scan.
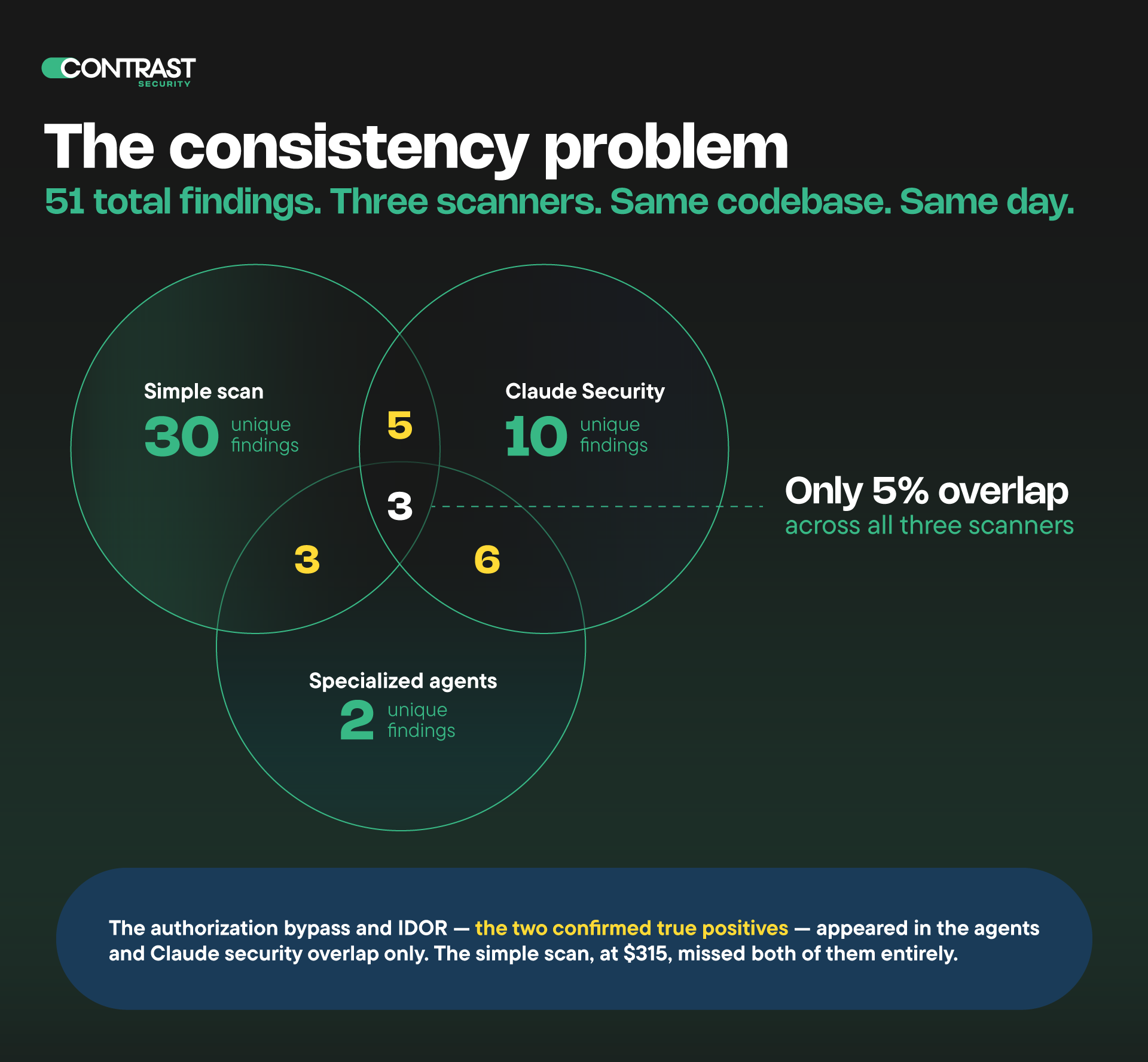
An important part of any AppSec program is getting consistent findings over multiple scans. This is critical so that teams can have a clear picture of where the risks lie, what’s been fixed and what’s left to address. Nobody wants to waste time chasing ghosts that appear and disappear seemingly at random.
LLMs are inherently non-deterministic, which poses a major challenge for a security tool seeking a single source of truth to underpin risk management. To see whether AI scanners could produce consistent results, we ran each AI scanner three times against the same 50,000 lines of Java. Here are the results:
The Simple Mode scan based on Sonnet 4.6 produced 45, 47 and 47 findings across its three runs, resulting in a 4.4% variance in counts. Only 6 of roughly 35 unique findings appeared in all three runs. That's a 17% reproducibility rate. Nearly half of all unique findings (49%) showed up in exactly one run and never again. Two Critical findings from one scan were dropped to High severity in another.
Upgrading to Opus was no better. It produced 32, 36, and 28 findings, a 28.6% swing between its best and worst run. Only 7 of roughly 28 unique findings appeared consistently. That's 25% reproducibility. The more expensive model was less stable in volume and only marginally more consistent in its findings. One Opus run called three Criticals while another called two against the exact same code.
Our testing shows the real challenges of getting reliable AppSec insights from commercial LLMs. This is not a tooling problem. It is how large language models work. Every inference is a fresh sample from a probability distribution. Running a single AI-powered security scan and calling your application reviewed might check a compliance box, but it’s not a useful basis for an enterprise AppSec program designed to manage down risk in a predictable manner.
If we have too many findings and not enough resources to sift through them all manually, the natural question is: can we use AI to cut through the noise? If so, can an AI be trusted to check its own work? And do the results change if we bring multiple models into the mix?
We began by testing the self-evaluation question. We took 523 findings generated by Claude and had Claude evaluate its own work. Claude confirmed only 1.1% of findings as true positives, while flagging 73% as requiring additional analysis due to some degree of uncertainty. Claude couldn’t commit to a verdict and left much of the work to human analysts to make the final decisions.
Shifting to a multi-model analysis improved things to some degree. We employed a panel of AIs, including Claude Opus 4.7, Gemini 2.5 Flash, and GPT-5.5, voting independently on each finding, with adjudication to come to a consensus result. Under this model, the AI jury confirmed 14.9% of the total findings as true positives, with 57% flagged for further analysis.
We'll chalk that up as a win for the multi-model approach, but one that comes with a significant caveat: we had security engineers review the results, and even with multi-model agreement, 50% of the remaining findings were still false positives. AI triage narrows the field significantly, but it does not replace an engineer's judgment. Many vulnerabilities that look critical in static code are either by design, constrained by runtime context, or require execution paths that don't exist in the actual application. A parameterized query might be flagged as an injection risk because the string formatting looks suspicious. A permission check might appear to be missing in isolation when it’s actually enforced at a higher architectural layer. An API endpoint might seem exposed until you trace how it's actually called in production. The multi-model consensus approach concentrated the signal to some degree, but it still left engineers to sort through mountains of patterns that look vulnerable in theory but function safely in practice.
On the fix side, while AI fixes can save developers a lot of time, they don't eliminate the need for human validation, testing and approval. If we have thousands of machine-generated pull requests queued against our production codebase, each one represents a change to production behavior that someone with context and accountability needs to review. And recall that 50% of the findings that made it through multi-model consensus were still false positives. Auto-applying fixes to code patterns that look vulnerable to a machine but function as designed in production introduces chaos and production risk. It will break working features, disrupt customer workflows and create a debugging crisis chasing changes that should never have been deployed.
We have in effect created another version of the triage problem, except now our engineers are reviewing AI-generated fixes on top of AI-generated findings. Add the computational cost of generating these thousands of fixes and the math gets worse.
So we keep iterating. We tighten the prompts, add deduplication logic, build orchestration layers to normalize output across runs, and integrate a faster deterministic scanner to anchor the AI’s findings to something repeatable. Each layer brings incremental improvements, but also adds cost, complexity and maintenance burden. At some point, you have to ask the honest question: when does “improving our AI scanning approach” become “building a new application security testing product from scratch”?
A quick analysis at scale shows that none of these approaches is likely to lead to success for most organizations. A mid-sized software company might have 50 meaningful repositories, each averaging 500,000 lines. Running the Simple Mode scan across all of them generates 10s of thousands of machine-generated findings that require dozens of security engineers' time and energy to analyze. Choose a different model, and you end up burning through millions of dollars in AI compute over a few weeks just to generate a smaller mountain of findings that are just as challenging to triage and remediate. No organization has these kinds of resources to spend on generating findings that no one will fix.
Fortunately and unfortunately, finding vulnerabilities has never been a hard problem in application security. Most organizations already have more findings than they can act on today. The fact is that the vast majority of these vulnerabilities never get weaponized. This is not because adversaries lack capability, but because turning a vulnerability into something usable requires that the vulnerable code be reachable, that the exploit work reliably across real target configurations, and that there are enough exposed targets to make building a campaign worthwhile. Most vulnerabilities fail at least one of those tests in most environments. Finding thousands of potential issues in your codebase does not change that calculus.
As an industry, the way forward is to stop optimizing for finding every possible vulnerability and start asking how we find the ones that actually matter. These are the vulnerabilities in your production environment that are reachable, being actively probed right now, and need to be contained before something breaks. Source code analysis can approximate reachability through dataflow and call-graph analysis, but it provides a static picture of a dynamic system. Runtime visibility tells you what is actually being hit today.
If you are running pure AI scanning today, do not throw it out. Put it where it belongs, in the development cycle, as one tool in a broader stack. AI brings reasoning about code context in ways traditional static tools cannot. Authorization flaws are a great example. Broken access control, IDOR, and missing ownership checks across complex multi-tenant logic are notoriously difficult to detect with pattern-matching SAST. AI understands the semantics of what a function is supposed to do and can identify when the required authorization check is missing. Our testing validates this: the authorization bypass and IDOR findings, the two strongest confirmed true positives in our dataset, were caught only by the AI-powered scanners.
The biggest AppSec gap for most organizations today is runtime visibility. You need to know what code is reachable by real traffic, what is being actively probed, and what needs your attention now rather than someday. This allows you to shift attention to KPIs that track real risk reduction. Mean Time To Remediate (MTTR) made sense when development moved at a pace that remediation could keep up with. It no longer does. The number that matters now is the Mean Time To Contain (MTTC). Not how fast did you fix it, but how fast did you know something was wrong and stop it from getting worse?
The scanner tax is real, and most organizations are paying it without knowing the full bill.
Frequently asked questions
What is the "AI scanner tax"?
The AI scanner tax is the hidden cost of AI-powered security scanning. The API fee is small. The real cost is the engineer’s time spent triaging what the scanner produces. A $315 scan that generates 3,560 findings costs roughly $128,000 in labor before a single vulnerability is fixed.
How accurate are AI security scanners?
In Contrast Labs testing, accuracy was poor across all three approaches. False positives were common across all price points. Three scanners analyzing the same codebase agreed on only 5% of findings. The two highest-confidence true positives (an authorization bypass and an IDOR flaw) were caught by the multi-agent scanner and Claude Security but missed by the simple scan entirely. False-negative rates are harder to quantify, but the 5% cross-scanner agreement rate suggests that each scanner is missing real findings that the others catch.
How much does AI security scanning cost for a large enterprise application?
For a 1.8-million-line codebase, a simple scan incurs roughly $315 in API costs and ~$128,000 in triage labor. A multi-agent approach runs $43,000-$107,000 in API costs alone, with all-in costs ranging from $65,000 to $150,000. Commercial scanners like Claude Security on a codebase this size are likely to cost $40,000-$50,000 in compute, based on observed scaling behavior.
Can AI security scanners replace traditional SAST tools?
No. AI scanning adds reasoning ability that pattern-matching SAST lacks, particularly for authorization flaws, broken access control, and IDOR. But it cannot replace deterministic tooling as the foundation of a production security program. Non-determinism is a fundamental characteristic of large language models: the same scanner run twice against the same code will return different results, making repeatable risk tracking impossible.
What is a realistic false positive rate for AI security scanners?
Contrast Labs did not calculate a single false-positive rate because it varied dramatically by approach and finding type. In qualitative review, a meaningful portion of high- and critical-severity findings from all three scanners were outright false positives or code patterns that were safe in context. Severity ratings were also inconsistent: two identical code patterns in the same codebase received different risk scores in the same scan.
Does spending more on AI scanning fix the noise problem?
No. Higher-quality scans produce better findings but do not eliminate false positives. The multi-agent approach found a real privilege-escalation issue with verified data flow. It also costs up to $107,000 per scan. The all-in cost (API plus triage) was not meaningfully different from the cheaper approach. Spending more shifts the cost structure. It does not solve it.
Should I use AI scanning at all?
Yes, in the right place. AI scanning belongs in the development cycle as one tool in a broader stack. It is particularly good at catching authorization and access control flaws that traditional SAST misses. What it cannot do is serve as the foundation of a production security program. For that, runtime visibility is the missing piece: knowing what code is reachable by real traffic, what is being actively probed, and what needs attention now.
What KPI should security teams use instead of MTTR?
Mean Time To Contain (MTTC). Mean Time To Remediate (MTTR) assumes remediation can keep pace with discovery. It can no longer. MTTC measures how quickly a team detects that something is wrong and stops it from getting worse. That is the metric that reflects actual risk reduction.
David Lindner is the CISO at Contrast Security.
Footnotes
1. Cycode, State of Product Security for the AI Era 2026. Veracode’s 2025 GenAI Code Security Report corroborates this trend, finding that 45% of AI-generated code samples introduced security vulnerabilities, with Java showing a 72% failure rate.
2. NIST, “NIST Updates NVD Operations to Address Record CVE Growth,” April 2026. nvd.nist.gov. CVE submissions increased 263% between 2020 and 2025, and NIST now prioritizes only CVEs appearing in CISA’s Known Exploited Vulnerabilities catalog, leaving the remainder unenriched.
3. Mandiant M-Trends 2025. The average time-to-exploit has fallen from 63 days in 2018-2019 to five days in 2024. Median organizational patching time is 32 days, leaving a 27-day exploitation window for most organizations.

David is an experienced application security professional with over 20 years in cybersecurity. In addition to serving as the chief information security officer, David leads the Contrast Labs team that is focused on analyzing threat intelligence to help enterprise clients develop more proactive approaches to their application security programs. Throughout his career, David has worked within multiple disciplines in the security field—from application development, to network architecture design and support, to IT security and consulting, to security training, to application security. Over the past decade, David has specialized in all things related to mobile applications and securing them. He has worked with many clients across industry sectors, including financial, government, automobile, healthcare, and retail. David is an active participant in numerous bug bounty programs.