X
November 10, 2021
A recently published paper provides a logo and slick polish for an old vulnerability about the ability of certain unicode characters to render differently for human reviewers than the machines that execute the instructions.
The code may intend to confuse a human reader to misunderstand the code based on how the compiler reads encoding (specifically unicode characters). The intended result would be to execute something that an unconfused human would not allow.
A human code reviewer using a plain-text editor or editor with inaccurate syntax-highlighting may miss the impact of these control characters. Most IDEs and code editors utilize parse trees and make the unicode characters visible so that it’s easier for someone to understand.
Developers discussing this Trojan Source vulnerability may use the opportunity to saddle up on horse puns.
The Trojan Source is a combination of unicode control characters that intend to confuse a human into thinking the code does one thing while getting the machine to do another. Mainly it involves the ability to change certain control characters like switching right-to-left encoding or to encode similar-looking letters in different character sets.
The paper also cites function name confusion where two methods have the same name but also not. It uses the example of two sayHello methods, one of which uses the Latin H and another function using the Cyrillic H (they both look the same). Code that calls the method will reference the machine-parsed function that can tell the difference.
The following code represents the example of these control characters to trick someone into thinking that the code will only print “You are an admin” if the accessLevel is not “user.” The code actually makes a different check, hiding a comment inside a String -- thus every user executes the admin statement.
package com.contrastsecurity.test;
public class TrojanSource {
public static void main(String[] args) {
String accessLevel = "user";
if (accessLevel != "user\u202E \u2066//Check if admin\u2069 \u2066") {
System.out.println("You are an admin.");
/* end admin only { */
}
}
}
Most IDEs render code in syntax-highlighted form that makes legibility easier. These don’t simply show neigh-kid plain text. Because developers spend multiple hours per day in a color-coded environment and often measure code reviews in WTFs, seeing mis-colored code will cause many to raise an equestrian question about what’s happening.
Similarly most static analyzers will detect and flag this type of code, mostly because it is confusing and hard to read.
GitHub will place a warning on files that contain bidirectional text control characters.

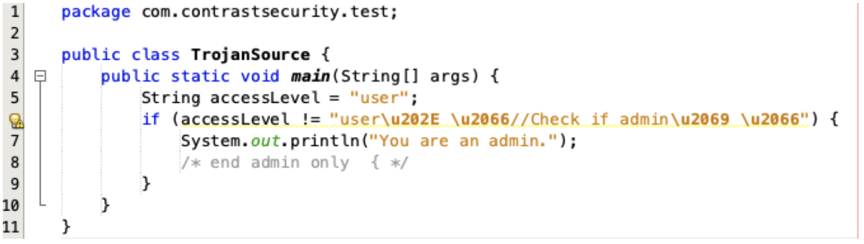
NetBeans properly interprets and color-codes the control characters.
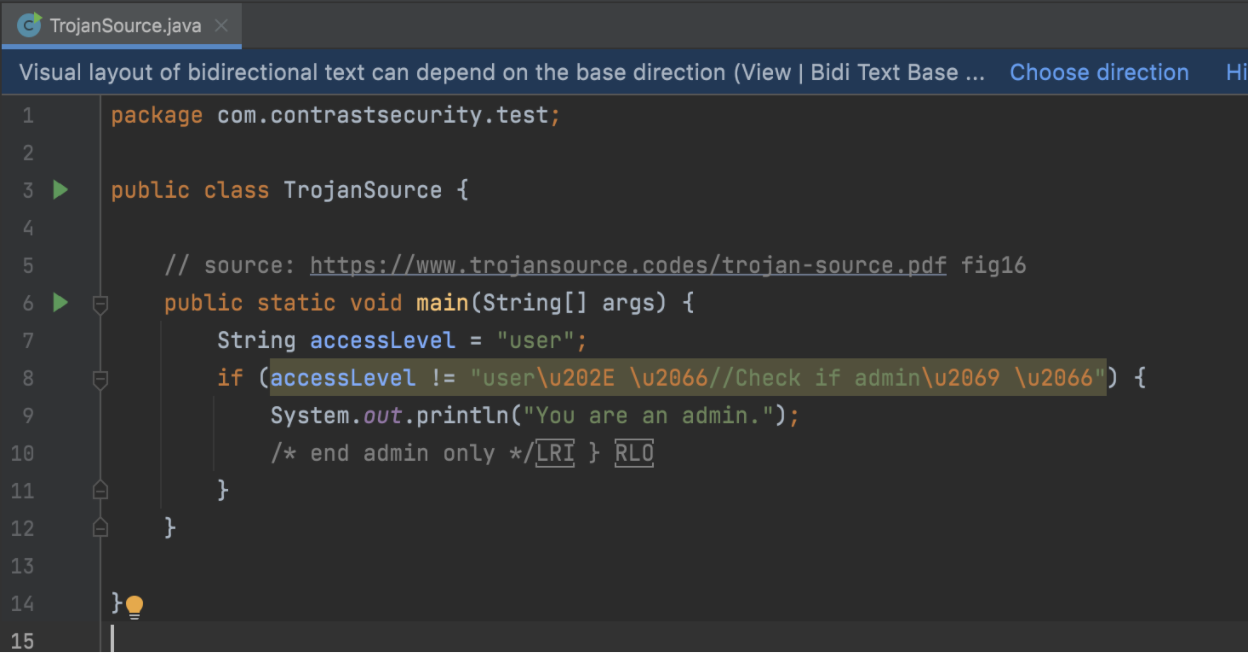
IntelliJ properly interprets and color-codes the control characters but incorrectly color-codes the comment -- it’s still clear that something is wrong. It also displays a banner at the top, indicating that there is bidirectional text.
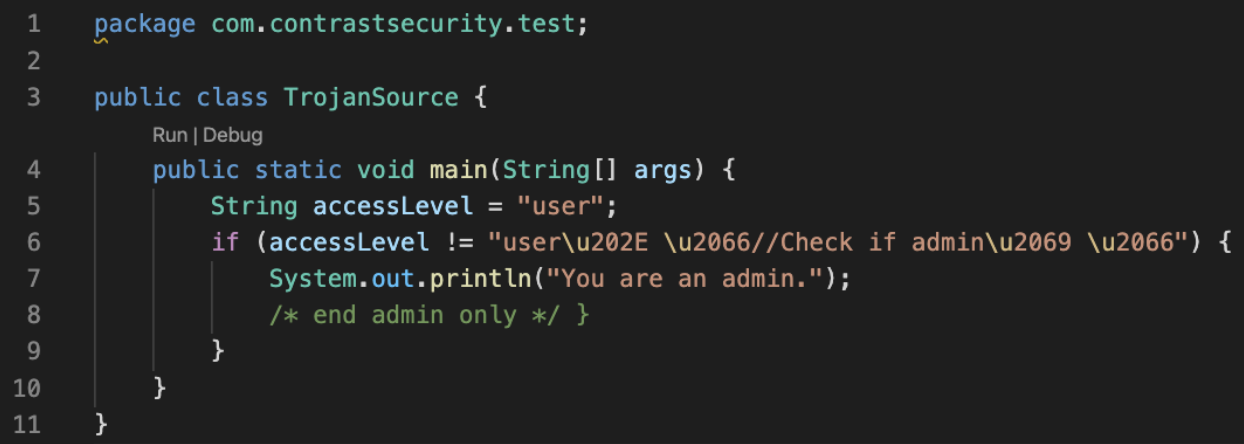
Visual Studio Code properly interprets and color-codes the control characters
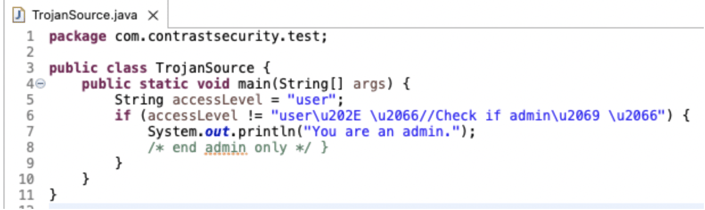
Eclipse properly interprets and color-codes the control characters.
Most security analyzers will simply walk past this attack, understanding the code like a machine rather than the human being tricked.
Common application security testing tools include:
Composition analysis at build time, to locate vulnerable dependencies.
Static analysis at build or commit time, to locate code-specific vulnerabilities.
Integrated analysis at testing, using an agent in the application to extract security context.
It’s unlikely that any of these tools will produce different results based on attempts to hide code with this Trojan Source attack. Composition analysis tools will be completely unaffected because they simply enumerate dependencies to locate which contain known CVEs.
Static analyzers typically won’t be fooled either. Many analyzers leverage bytecode in addition to source code, and those that do work on source code will parse code with a grammar that properly navigates the unicode controls. In the screenshots above, some IDEs were already citing quality issues in the unicode snippet.
Integrated Analyzers will still generate full security results from an application, because they focus on the code that executes. As a result the analyzers will still produce a full suite of security results to find issues like injection flaws, weak cryptography usage, or other types of flaw.
While malicious actors could submit pull requests with unicode control characters, they are relatively easy to spot.
Another defense in the Java ecosystem is the separation of bytecode from source code, and the fact that many tools (such as static and integrated analyzers) work on the bytecode. This is done because machines run and JIT compile the bytecode and often source code isn’t present for libraries. Another attack would be simply to provide one piece of source code but compile a different binary with additional statements.
For the Trojan Source, the intent is clearly laid out in bytecode. All Java compilers for any JDK will produce the same or extremely similar output because the connection to unicode characters is spelled out in the Java Language Specification, Chapter 3, section 3: Unicode Escapes.
A separate tool, javap, is distributed to simplify a developer’s ability to look at the bytecode. Bytecode is an intermediate form of compiled code that is intended to also be read by humans -- as such it can be inspected, decompiled, and so on. While most people don’t actually look at bytecode and it’s unreasonable to expect that most people do, the important distinction is that many or most tools do look at bytecode and would see the result of any Trojan Source attempts.

In this bytecode, we see the first LDC (load constant) operation define the word “user” to represent the access level. Code 4 represents the full String that is color-coded by the different IDEs, representing the attempt to hide code (which is not hidden from bytecode). The comparison IF_ACMPEQ on code 6 compares the previous stack constant “user” to this other String “user //Check if admin” and if true jumps to the return.
With the Java community’s common use of tooling, it’s unlikely that Trojan Source attacks would have a notable impact on Java projects beyond hard-to-read-but-malicious code contributions.
No. Most development teams want legible code and reject illegible code. Most likely the industry will simply flag source files that contain this attack, more for legibility and cognitive reasons than for security. Characters may be allowed only in certain multi-language files or in translation bundles for specific languages rather than coded into files.
While the compiler may seem like an effective location for defense, the flaw is in unicode interpretation and would still impact parsers that read other types of data. A proper defense is to focus project work on legibility and separating code from data. An old quote from Donald Knuth applies, “Programs are meant to be read by humans and only incidentally for computers to execute.”
Reject code that contains illegible unicode encoding characters on the grounds that they are hard to read and will impact project maintainability.
When dealing with translated data that does require some unicode, place that data into separate translation files. Separating it from the code will also make it easier to change.